Historical Background
From the past to the present, machine translation (MT) has seen an increase in demand and an expansion of its application. The definition of machine translation, its historical background, methods for assessing its quality, and their significance in relation to the Turkish language will be covered here.
The concept of machine translation dates back to the 17th century, yet actual steps in the field were not taken until the invention of computers in the middle of the 20th century. During that period, famous philosophers such as Descartes, Mersenne, and Leibniz considered the potential of employing numerical codes to facilitate universal communication. The lack of advanced technology at the time, however, precluded these ideas from progressing beyond the theoretical stage. The enormous advancements in computing technology and the growing demand and necessity for machine translation drove scholars to carry out new studies in the 20th century. Rule-based strategies were utilized in the beginning. However, it was not possible to have consistent and reliable outputs due to the intricacy of these methods and their inability to adequately capture the underlying structure of languages. Later, techniques for statistical machine translation were brought out. By utilizing vast datasets, these algorithms sought to get beyond restrictions based on grammatical constraints. After years of statistical systems dominating the field of machine translation, a novel system utilizing neural networks has become quite popular. The advent of the neural-based machine translation system (NMT) by Google in 2016 has made a radical revolution in the field of machine translation. Personally, I do not find it wrong to call this new system as the updated and amalgamated version of statistical machine translation in that it also uses large sets of bilingual corpora with the combination of neural networks. Furthermore, the main aim of Google was to reduce the deficiencies of statistical systems with the use of neural networks. They did not fail, indeed. The dominating performance of NMT set the bar too high and pushed other companies to use neural-based systems as well. By utilizing artificial intelligence (AI) and deep learning approaches, NMT systems are now
experiencing even further improvements in their performances. As a result, the outputs of MT systems have higher degrees of accuracy and naturalness.
Methods for Evaluating Quality
Evaluating the quality of machine translation systems is a very important process. These systems will be much more effective if the usability and accuracy of the results are determined, and improvements are implemented based on the findings. The two basic methods for evaluating quality are automatic and human evaluation.
In order to evaluate the translation quality, linguists or experienced translators conduct human evaluations with the use of a particular error analysis guide (such as MQM) as a point of reference. These assessments take into account a variety of fundamental error issues, including those related to accuracy, fluency, consistency, meaning, and style. In general, human review is argued to yield better results. It takes a lot of time and money, though. On the other hand, while automatic metrics are quicker and less expensive, they may produce inaccurate data. The hybrid strategy, which combines the two approaches, is therefore thought to produce the best outcomes.
The Turkish Context
As mentioned above, Google launched NMT systems in 2016. They made a point of stating in their release that their new technology only supported eight languages. What about Turkish? Was it included? The answer is yes. Turkish was included as one of the supported languages by this new system. This highlights the importance of the Turkish language and the amount of content generated in this language.
So, where does this significance of Turkish in the context of machine translation lead the researchers in translation studies? Of course, it pushes us to carry out studies on quality assessment. Unfortunately, there is a significant gap on evaluating the quality of machine translations in the context of Turkish. So, the question is how well different MT systems work in Turkish-English and English-Turkish translation processes. Under the supervision of Asst. Prof. Muhammed BAYDERE at Karadeniz Technical University, I conducted a BA graduation thesis project last year that was supported by the TUBITAK 2209 program focusing on machine translation error analysis and the quality evaluation. field of translation.
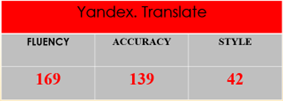
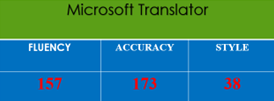
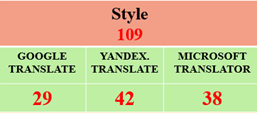
In this study, we compared how well Google Translate (GT), Yandex. Translate (YT), and Microsoft Translator (Mt) translated culinary texts embedded with culture-specific items in the Turkish-English and English-Turkish language pairs. For this reason, two Turkish and two English culinary texts were selected from a blog on Instagram. Then, these texts were translated in the three mentioned translation engines. After that, 12 gathered outputs were annotated based on the MQM error categories of accuracy, fluency, and style by three human annotators who have 10 years of experience in the field of translation.
Findings Overall
The study’s findings revealed that the performance of the aforementioned translation engines varied significantly. Comparing GT to the other two translation engines, it produced significantly better outputs. On the other hand, Mt and YT performed quite similarly. Yet, YT performed slightly better than Mt (see figure 1).
Figure 1. Total Errors