

Understanding Large Language Models: Beginner’s Guide
In recent years, artificial intelligence has profoundly reshaped numerous domains, with Large Language Models (LLMs) emerging as one of the most transformative innovations. A large language model is a type of neural network trained on vast corpora of text data sourced from the internet, including books, scientific articles, websites, social media posts (e.g., tweets), subtitles, transcripts, and other publicly available textual resources.

A fundamental distinction separates LLMs from traditional programming paradigms. In conventional programming languages such as Python or JavaScript, developers explicitly define rules and logic through imperative instructions (e.g., “if condition X is met, then execute action Y”). In contrast, LLMs are not programmed with explicit rules. Instead, they acquire linguistic and factual knowledge through statistical learning: during pre-training, the model is exposed to trillions of tokens and repeatedly tasked with predicting the next token in a sequence. This simple yet powerful objective enables the model to internalize grammar, semantics, factual associations, and even reasoning patterns.
For example, when presented with the partial sentence “Istanbul is a city in …” a well-trained LLM will predict “Türkiye” with the highest probability while assigning lower (yet plausible) probabilities to related continuations such as “Turkey,” “the Republic of Türkiye,” or longer explanatory phrases like “Türkiye, straddling the continents of Europe and Asia.” This next token prediction mechanism, executed autoregressively, underlies the remarkable flexibility and generative capabilities of modern LLMs.
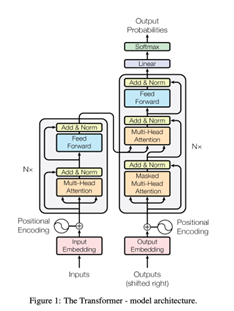
Although research on conversational agents dates back to the 1960s, notably Joseph Weizenbaum’s rule-based ELIZA system (1966), the architecture that enabled today’s LLMs was introduced in 2017. In their seminal paper “Attention Is All You Need,” Vaswani et al. proposed the Transformer architecture, which replaced recurrent and convolutional layers with a self-attention mechanism. Virtually all state-of-the-art LLMs in 2025 (including GPT series, LLaMA, Claude, Gemini, Grok, and others) are direct descendants of this Transformer paradigm.
In essence, LLMs have shifted the paradigm of human–computer interaction in language tasks from rigid instruction-following to probabilistic pattern completion at scale, marking a pivotal evolution in natural language processing.
Transformer Model
Until the Transformer arrived, the standard way to handle language with deep learning was a type of model called a Recurrent Neural Network (RNN). For example, if we wanted to translate a sentence from English to Turkish, an RNN would read the English words one by one, from left to right, and then generate the Turkish sentence the same way: sequentially. This step-by-step processing was necessary because word order matters enormously in language; even a single comma can change the meaning. The problem was that RNNs struggled badly with long texts. Once a sentence or document reached hundreds or thousands of words, the model tended to “forget” what came earlier, and training was painfully slow. That is when the Transformer changed everything. In 2017, a team (mostly from Google and the University of Toronto) published the legendary paper “Attention Is All You Need.” They originally built the Transformer to solve machine translation, and it crushed every previous system. Nobody at the time (probably not even the authors) realized that this same architecture would later power ChatGPT, Grok, Claude, Gemini, and basically every large language model we use today. The revolutionary idea was simple but powerful: instead of reading text one word at a time, the Transformer looks at all the words at the same time and asks, “Which words are most relevant to understanding or predicting this particular word?” This is done with a mechanism called self-attention.
Take the classic example:
“The cat that chased the mouse which ate the cheese is black.”
When the model reaches the word “is” (or “black”), it instantly knows that “is” refers to “cat,” no matter how many words are in between. Old RNNs usually lose that connection; the Transformer never does. Thanks to self-attention and full parallel processing, Transformers can handle huge amounts of text, train much faster, and scale to billions or trillions of parameters. So yes, the technology that now runs translations, chatbots, and almost everything else in modern AI started in 2017 with one goal: to translate sentences better than ever before.
How do LLMs interact with the Machine Translation world?
LLMs have completely revolutionized the translation field in the last 5–6 years. In professional workflows, translators no longer start from scratch. They run the source text through an advanced LLM, get a near-perfect first draft in seconds, and then spend their time refining style, double checking specialized terms, or adapting cultural references.
So why do LLMs crush the old translation systems?
- They have seen way more text than any human ever could, trillions of words in hundreds of languages.
- Every word gets turned into a giant vector (a list of thousands of numbers) in a shared hidden space, so “dog” in English ends up close to “perro” in Spanish and “köpek” in Turkish because they mean the same thing.
- Thanks to self-attention, the model can look at the entire document at once instead of translating sentence by sentence, so terminology stays consistent and the tone feels natural all the way through.
- You don’t even need to fine-tune them anymore, just give a clear prompt (like “Translate to German, keep the sarcastic tone”) and it usually nails it on the first try.

Sure, closely related languages (English ↔ French) are still a bit easier than distant ones (English ↔ Korean), but the gap has shrunk so much that it barely matters for most real-world jobs. In summary, LLMs have not merely improved machine translation; they have become the dominant paradigm, reshaping economic models, professional practices, and accessibility to information across the world’s languages.
From a translation studies perspective, however, it is important to note that LLMs do not simply “translate” in the traditional sense. Rather than constructing meaning, they generate statistically probable sequences that simulate equivalence. This raises critical questions about the nature of translation itself: Is a fluent output necessarily an accurate one? And what happens when meaning, culture, and intention are reduced to patterns in data? In this sense, LLMs do not replace translators but transform their role from text producers into meaning evaluators.
References:
- Google Cloud Tech. (2021, August 18). Transformers, explained: Understand the model behind GPT, BERT, and T5., YouTube. https://www.youtube.com/watch?v=SZorAJ4I-sA
- Matthew Berman. (2024, March 7)How large language models work [https://www.youtube.com/watch?v=osKyvYJ3PRM ] YouTube.
- Naveed, H., Khan, A. U., Qiu, S., Saqib, M., Anwar, S., Usman, M., Akhtar, M. N., Barnes, N., & Mian, A. (2025). A comprehensive overview of large language models. ACM Transactions on Intelligent Systems and Technology, 16(5), Article 98 (1–72). https://doi.org/10.1145/3665870
- Vagner, L., & Melichar, B. (2007). Formal translation directed by parallel LLP parsing. In J. van Leeuwen, O. B. de Bruin, & G. F. Italiano (Eds.), Current trends in theory and practice of computer science: 33rd Conference on Current Trends in Theory and Practice of Computer Science, SOFSEM 2007, Harrachov, Czech Republic, January 20–26, 2007. Proceedings (pp. 532–543). Springer. https://doi.org/10.1007/978-3-540-69507-1_47
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. arXiv. https://arxiv.org/abs/1706.03762
- 3Blue1Brown. (2024, November 20). LLM [https://www.youtube.com/watch?v=LPZh9BOjkQs] YouTube.
AI Use
- This article was edited for language and clarity with the assistance of artificial intelligence (Grok, developed by xAI). All images were generated using AI tools, with the exception of Figure 1.



